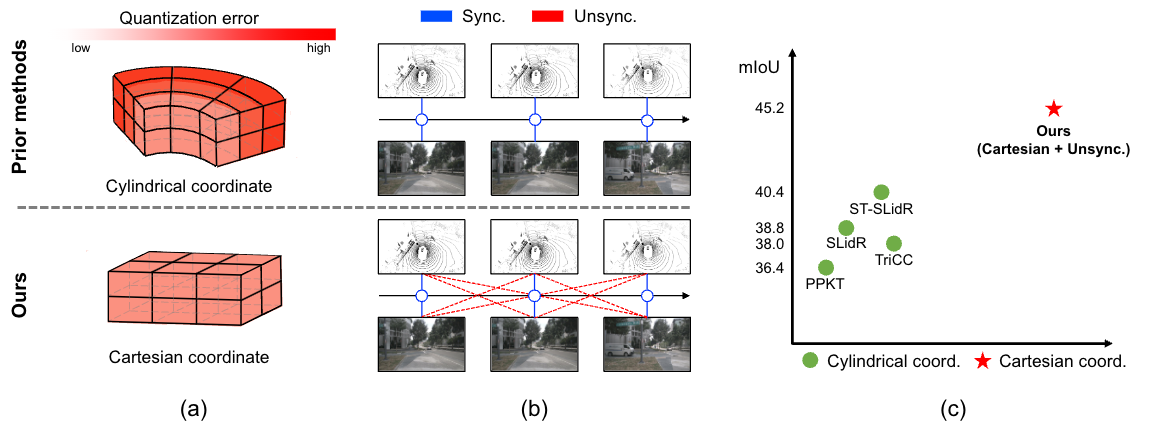
LiDAR is a crucial sensor in autonomous driving, commonly used alongside cameras. By exploiting this camera-LiDAR setup and recent advances in image representation learning, prior studies have shown the promising potential of image-to-LiDAR distillation. These prior arts focus on the designs of their own losses to effectively distill the pre-trained 2D image representations into a 3D model. However, the other parts of the designs have been surprisingly unexplored. We find that fundamental design elements, e.g., the LiDAR coordinate system, quantization according to the existing input interface, and data utilization, are more critical than developing loss functions, which have been overlooked in prior works. In this work, we show that simple fixes to these designs notably outperform existing methods by 16% in 3D semantic segmentation on the nuScenes dataset and 13% in 3D object detection on the KITTI dataset in downstream task performance. We focus on overlooked design choices along the spatial and temporal axes. Spatially, prior work has used cylindrical coordinate and voxel sizes without considering their side effects yielded with a commonly deployed sparse convolution layer input interface, leading to spatial quantization errors in 3D models. Temporally, existing work has avoided cumbersome data curation by discarding unsynced data, limiting the use to only the small portion of data that is temporally synced across sensors. We analyze these effects and propose simple solutions for each overlooked aspect.

This project was supported by RideFlux and also supported by the Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government(MSIT) (No.RS-2022-II220124, Development of Artificial Intelligence Technology for Self-Improving CompetencyAware Learning Capabilities; No. 2020-0-00004, Development of Previsional Intelligence based on Long-term Visual Memory Network; No.RS-2020-II201336, Artificial Intelligence Graduate School Program(UNIST))
@InProceedings{Jo_2024_ACCV,
author = {Jo, Wonjun and Byung-Ki, Kwon and Ji-Yeon, Kim and Jeong, Hawook and Joo, Kyungdon and Oh, Tae-Hyun},
title = {The Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning},
booktitle = {Proceedings of the Asian Conference on Computer Vision (ACCV)},
month = {December},
year = {2024},
pages = {3172-3188}
}